
Grandes modelos de linguagem (LLMs), como GPT, LLaMA e outros, conquistaram o mundo com sua notável capacidade de compreender e gerar texto semelhante ao humano. No entanto, apesar das suas capacidades impressionantes, o método padrão de treino destes modelos, conhecido como “previsão do próximo token”, tem algumas limitações inerentes.
Na previsão do próximo token, o modelo é treinado para prever a próxima palavra em uma sequência, dadas as palavras anteriores. Embora esta abordagem tenha se mostrado bem-sucedida, ela pode levar a modelos que enfrentam dependências de longo alcance e tarefas de raciocínio complexas. Além disso, a incompatibilidade entre o regime de formação forçada dos professores e o processo de geração autoregressiva durante a inferência pode resultar num desempenho abaixo do splendid.
Um artigo de pesquisa recente de Gloeckle et al. (2024) da Meta AI apresenta um novo paradigma de treinamento chamado “previsão de vários tokens”que visa resolver essas limitações e turbinar grandes modelos de linguagem. Nesta postagem do weblog, nos aprofundaremos nos principais conceitos, detalhes técnicos e implicações potenciais desta pesquisa inovadora.
O que é previsão de vários tokens?
A ideia principal por trás da previsão de vários tokens é treinar modelos de linguagem para prever vários tokens futuros simultaneamente, em vez de apenas o próximo token. Especificamente, durante o treinamento, o modelo tem a tarefa de prever os próximos n tokens em cada posição no corpus de treinamento, usando n cabeças de saída independentes operando no topo de um tronco de modelo compartilhado.
Por exemplo, com uma configuração de previsão de 4 tokens, o modelo seria treinado para prever os próximos 4 tokens de uma vez, dado o contexto anterior. Esta abordagem incentiva o modelo a captar dependências de longo prazo e a desenvolver uma melhor compreensão da estrutura geral e da coerência do texto.
Um exemplo de brinquedo
Para entender melhor o conceito de previsão de vários tokens, vamos considerar um exemplo simples. Suponha que tenhamos a seguinte frase:
“A rápida raposa marrom salta sobre o cachorro preguiçoso.”
Na abordagem padrão de previsão do próximo token, o modelo seria treinado para prever a próxima palavra, dado o contexto anterior. Por exemplo, dado o contexto “A rápida raposa marrom salta sobre o”, o modelo teria a tarefa de prever a próxima palavra, “preguiçoso”.
Com a previsão de vários tokens, entretanto, o modelo seria treinado para prever várias palavras futuras de uma só vez. Por exemplo, se definirmos n=4, o modelo seria treinado para prever as próximas 4 palavras simultaneamente. Dado o mesmo contexto “A rápida raposa marrom salta sobre o”, o modelo teria a tarefa de prever a sequência “cachorro preguiçoso”. (Observe o espaço após “cachorro” para indicar o last da frase).
Ao treinar o modelo para prever vários tokens futuros de uma só vez, é incentivado a capturar dependências de longo alcance e a desenvolver uma melhor compreensão da estrutura geral e da coerência do texto.
Detalhes técnicos
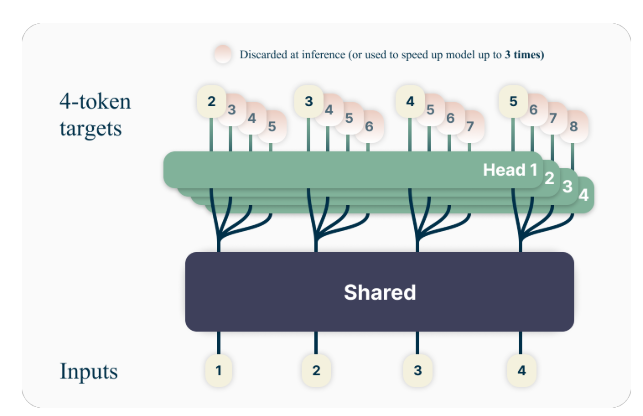
Os autores propõem uma arquitetura simples, mas eficaz para implementar a previsão de vários tokens. O modelo consiste em um tronco transformador compartilhado que produz uma representação latente do contexto de entrada, seguido por n camadas de transformadores independentes (cabeças de saída) que prevêem os respectivos tokens futuros.
Durante o treinamento, as passagens para frente e para trás são cuidadosamente orquestradas para minimizar o consumo de memória da GPU. O tronco compartilhado calcula a representação latente e então cada cabeça de saída executa sequencialmente sua passagem para frente e para trás, acumulando gradientes no nível do tronco. Essa abordagem evita a materialização de todos os vetores logit e seus gradientes simultaneamente, reduzindo o pico de uso de memória da GPU de O(nV + d) para SOBRE(V + d)onde V é o tamanho do vocabulário e d é o dimensão da representação latente.
A implementação com eficiência de memória
Um dos desafios no treinamento de preditores de vários tokens é reduzir a utilização da memória da GPU. Desde o tamanho do vocabulário (V) normalmente é muito maior que o dimensão da representação latente (d)os vetores logit se tornam o gargalo de uso da memória da GPU.
Para enfrentar esse desafio, os autores propõem uma implementação com uso eficiente de memória que adapta cuidadosamente a sequência de operações para frente e para trás. Em vez de materializar todos os logits e seus gradientes simultaneamente, a implementação calcula sequencialmente os passes para frente e para trás para cada cabeça de saída independente, acumulando gradientes no nível do tronco.
Essa abordagem evita armazenar todos os vetores logit e seus gradientes na memória simultaneamente, reduzindo o pico de utilização da memória da GPU de O(nV + d) para SOBRE(V + d)onde n é o número de tokens futuros previstos.
Vantagens da previsão de vários tokens
O artigo de pesquisa apresenta várias vantagens atraentes do uso da previsão de vários tokens para treinar grandes modelos de linguagem:
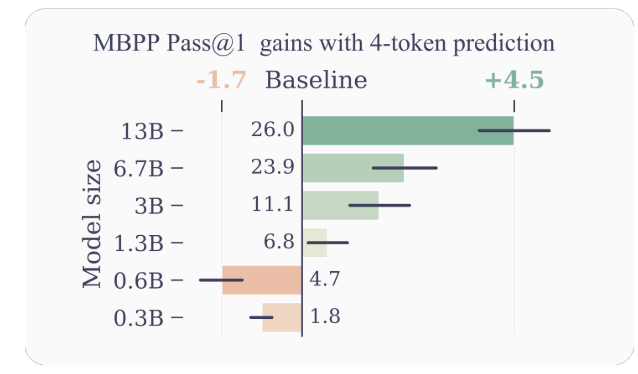
- Eficiência de amostra aprimorada: Ao encorajar o modelo a prever vários tokens futuros de uma só vez, a previsão de vários tokens leva o modelo a uma melhor eficiência da amostra. Os autores demonstram melhorias significativas no desempenho em tarefas de compreensão e geração de código, com modelos de até 13B de parâmetros resolvendo em média cerca de 15% mais problemas.
- Inferência mais rápida: Os cabeçotes de saída adicionais treinados com previsão de vários tokens podem ser aproveitados para decodificação autoespeculativa, uma variante da decodificação especulativa que permite a previsão de token paralela. Isso resulta em tempos de inferência até 3x mais rápidos em uma ampla variedade de tamanhos de lote, mesmo para modelos grandes.
- Promovendo Dependências de Longo Alcance: a previsão de vários tokens incentiva o modelo a capturar dependências e padrões de longo alcance nos dados, o que é particularmente benéfico para tarefas que exigem compreensão e raciocínio em contextos maiores.
- Raciocínio Algorítmico: Os autores apresentam experimentos em tarefas sintéticas que demonstram a superioridade de modelos de predição multitoken no desenvolvimento de cabeças de indução e capacidades de raciocínio algorítmico, especialmente para modelos menores.
- Coerência e consistência: Ao treinar o modelo para prever vários tokens futuros simultaneamente, a previsão de vários tokens incentiva o desenvolvimento de representações coerentes e consistentes. Isto é particularmente benéfico para tarefas que exigem a geração de textos mais longos e coerentes, como contar histórias, escrita criativa ou geração de manuais de instrução.
- Generalização Melhorada: Os experimentos dos autores em tarefas sintéticas sugerem que os modelos de previsão de múltiplos tokens exibem melhores capacidades de generalização, especialmente em ambientes fora de distribuição. Isto se deve potencialmente à capacidade do modelo de capturar padrões e dependências de longo alcance, o que pode ajudá-lo a extrapolar de forma mais eficaz para cenários invisíveis.

Exemplos e Intuições
Para fornecer mais intuição sobre por que a previsão de vários tokens funciona tão bem, vamos considerar alguns exemplos:
- Geração de código: No contexto da geração de código, a previsão de vários tokens simultaneamente pode ajudar o modelo a compreender e gerar estruturas de código mais complexas. Por exemplo, ao gerar uma definição de função, prever apenas o próximo token pode não fornecer contexto suficiente para que o modelo gere corretamente toda a assinatura da função. No entanto, ao prever vários tokens de uma vez, o modelo pode capturar melhor as dependências entre o nome da função, os parâmetros e o tipo de retorno, levando a uma geração de código mais precisa e coerente.
- Raciocínio em Linguagem Pure: considere um cenário em que um modelo de linguagem tem a tarefa de responder a uma pergunta que requer raciocínio sobre várias etapas ou informações. Ao prever vários tokens simultaneamente, o modelo pode capturar melhor as dependências entre os diferentes componentes do processo de raciocínio, levando a respostas mais coerentes e precisas.
- Geração de texto longo: ao gerar textos longos, como histórias, artigos ou relatórios, manter a coerência e a consistência por um longo período pode ser um desafio para modelos de linguagem treinados com previsão do próximo token. A previsão de vários tokens incentiva o modelo a desenvolver representações que capturem a estrutura geral e o fluxo do texto, potencialmente levando a gerações de formato longo mais coerentes e consistentes.
Limitações e direções futuras
Embora os resultados apresentados no artigo sejam impressionantes, existem algumas limitações e questões em aberto que merecem uma investigação mais aprofundada:
- Número splendid de tokens: O artigo explora diferentes valores de n (o número de tokens futuros a serem previstos) e descobre que n=4 funciona bem para muitas tarefas. No entanto, o valor splendid de n pode depender da tarefa específica, do conjunto de dados e do tamanho do modelo. O desenvolvimento de métodos baseados em princípios para determinar o n splendid poderia levar a novas melhorias de desempenho.
- Tamanho do vocabulário e tokenização: Os autores observam que o tamanho splendid do vocabulário e a estratégia de tokenização para modelos de previsão de vários tokens podem diferir daqueles usados para modelos de previsão de próximo token. Explorar esse aspecto poderia levar a melhores compensações entre o comprimento da sequência compactada e a eficiência computacional.
- Perdas de previsão auxiliares: Os autores sugerem que seu trabalho pode estimular o interesse no desenvolvimento de novas perdas de previsão auxiliares para grandes modelos de linguagem, além da previsão padrão do próximo token. Investigar perdas auxiliares alternativas e suas combinações com previsão de múltiplos tokens é uma direção de pesquisa interessante.
- Compreensão Teórica: Embora o artigo forneça algumas intuições e evidências empíricas para a eficácia da previsão de vários tokens, seria valiosa uma compreensão teórica mais profunda de por que e como essa abordagem funciona tão bem.
Conclusão
O artigo de pesquisa “Modelos de linguagem grande melhores e mais rápidos through previsão de vários tokens” de Gloeckle et al. introduz um novo paradigma de treinamento que tem o potencial de melhorar significativamente o desempenho e as capacidades de grandes modelos de linguagem. Ao treinar modelos para prever vários tokens futuros simultaneamente, a previsão de vários tokens incentiva o desenvolvimento de dependências de longo alcance, habilidades de raciocínio algorítmico e melhor eficiência da amostra.
A implementação técnica proposta pelos autores é elegante e computacionalmente eficiente, tornando viável a aplicação desta abordagem ao treinamento de modelos de linguagem em larga escala. Além disso, a capacidade de aproveitar a decodificação autoespeculativa para inferências mais rápidas é uma vantagem prática significativa.
Embora ainda existam questões em aberto e áreas para exploração adicional, esta pesquisa representa um passo emocionante no campo dos grandes modelos de linguagem. À medida que a procura por modelos de linguagem mais capazes e eficientes continua a crescer, a previsão de múltiplos tokens pode tornar-se um componente chave na próxima geração destes poderosos sistemas de IA.




