
O desenvolvimento e o progresso dos modelos de linguagem nos últimos anos marcaram a sua presença em quase todo o lado, não unicamente na investigação da PNL, mas também em ofertas comerciais e aplicações do mundo real. No entanto, o aumento da procura mercantil de modelos linguísticos tem, até manifesto ponto, dificultado o propagação da comunidade. Isso ocorre porque a maioria dos modelos capazes e de última geração são protegidos por interfaces proprietárias, impossibilitando que a comunidade de desenvolvimento acesse detalhes vitais de sua arquitetura de treinamento, dados e processos de desenvolvimento. É agora inegável que esta formação e detalhes estruturais são cruciais para os estudos de investigação, incluindo o entrada aos seus potenciais riscos e preconceitos, criando assim um requisito para que a comunidade de investigação tenha entrada a um protótipo de linguagem verdadeiramente crédulo e poderoso.
Para atender a esse requisito, os desenvolvedores criaram o OLMo, uma estrutura de protótipo de linguagem verdadeiramente ensejo e de última geração. Esta estrutura permite que pesquisadores usem o OLMo para erigir e estudar modelos de linguagem. Ao contrário da maioria dos modelos de linguagem de última geração, que lançaram unicamente código de interface e pesos de protótipo, a estrutura OLMo é verdadeiramente de código crédulo, com código de avaliação, métodos e dados de treinamento acessíveis ao público. O objetivo principal do OLMo é capacitar e impulsionar a comunidade de pesquisa ensejo e o desenvolvimento contínuo de modelos linguísticos.
Neste cláusula, discutiremos detalhadamente a estrutura OLMo, examinando sua arquitetura, metodologia e desempenho em conferência com as estruturas de última geração atuais. Portanto vamos principiar.
OLMo: Aprimorando a Ciência dos Modelos de Linguagem
O protótipo de linguagem tem sido indiscutivelmente a tendência mais quente nos últimos anos, não unicamente na comunidade de IA e ML, mas também em toda a indústria tecnológica, devido às suas notáveis capacidades na realização de tarefas do mundo real com desempenho semelhante ao humano. ChatGPT é um magnífico exemplo do potencial dos modelos de linguagem, com os principais players da indústria de tecnologia explorando a integração do protótipo de linguagem com seus produtos.
PNL, ou Processamento de Linguagem Oriundo, é uma das indústrias que empregou extensivamente modelos de linguagem nos últimos anos. No entanto, desde que a indústria começou a empregar lembrete humana para alinhamento e pré-treinamento em larga graduação, os modelos de linguagem testemunharam um rápido aprimoramento em sua viabilidade mercantil, resultando na restrição da maioria das linguagens de última geração e estruturas de PNL. interfaces proprietárias, com a comunidade de desenvolvimento não tendo entrada a detalhes vitais.
Para prometer o progresso dos modelos de linguagem, o OLMo, um protótipo de linguagem verdadeiramente crédulo e de última geração, oferece aos desenvolvedores uma estrutura para erigir, estudar e seguir no desenvolvimento de modelos de linguagem. Ele também fornece aos pesquisadores entrada ao seu código de treinamento e avaliação, metodologia de treinamento, dados de treinamento, registros de treinamento e pontos de verificação de protótipo intermediário. Os modelos de última geração existentes têm vários graus de orifício, enquanto o protótipo OLMo liberou toda a estrutura, desde o treinamento até os dados e as ferramentas de avaliação, diminuindo assim a vazio de desempenho quando comparado com modelos de última geração uma vez que o protótipo LLaMA2.
Para modelagem e treinamento, a estrutura OLMo inclui o código de treinamento, pesos completos do protótipo, ablações, registros de treinamento e métricas de treinamento na forma de código de interface, muito uma vez que registros de Pesos e Vieses. Para estudo e construção de conjuntos de dados, a estrutura OLMo inclui os dados de treinamento completos usados para os modelos Dolma e WIMBD do AI2, juntamente com o código que produz os dados de treinamento. Para fins de avaliação, a estrutura OLMo inclui o protótipo Catwalk do AI2 para avaliação downstream e o protótipo Paloma para avaliação baseada em perplexidade.
OLMo: Protótipo e Arquitetura
O protótipo OLMo adota uma arquitetura de transformador somente decodificador baseada nos Sistemas de Processamento de Informações Neurais e oferece dois modelos com 1 bilhão e 7 bilhões de parâmetros respectivamente, com um protótipo de 65 bilhões de parâmetros atualmente em desenvolvimento.
A arquitetura da estrutura OLMo oferece várias melhorias em relação às estruturas, incluindo o componente Vanilla Transformer em sua arquitetura, incluindo modelos de linguagem de grande porte de última geração, uma vez que OpenLM, Falcon, LLaMA e PaLM. A figura a seguir compara o protótipo OLMo com 7 bilhões de parâmetros com LLMs recentes operando em números quase iguais de parâmetros.

A estrutura OLMo seleciona os hiperparâmetros otimizando o protótipo para o rendimento do treinamento no hardware e, ao mesmo tempo, minimizando o risco de divergência lenta e picos de perda. Dito isto, as principais alterações implementadas pela estrutura OLMo que se distingue da arquitetura do transformador vanilla são as seguintes:
Sem preconceitos
Ao contrário do Falcon, PaLM, LLaMA e outros modelos de linguagem, a estrutura OLMo não inclui qualquer preconceito na sua arquitetura para melhorar a segurança do treinamento.
Norma de estrato não paramétrica
O framework OLMo implementa a formulação não paramétrica da norma da estrato em sua arquitetura. A Norma da Categoria Não Paramétrica não oferece transformação idêntico dentro da norma, ou seja, não oferece nenhum lucro adaptativo ou viés. As normas de estrato não paramétrica não unicamente oferecem mais segurança que as normas de estrato paramétrica, mas também são mais rápidas.
Função de ativação SwiGLU
Porquê a maioria dos modelos de linguagem uma vez que PaLM e LLaMA, a estrutura OLMo inclui a função de ativação SwiGLU em sua arquitetura em vez da função de ativação ReLU e aumenta o tamanho da ativação oculta para o múltiplo mais próximo de 128 para melhorar o rendimento.
RoPE ou Embeddings Posicionais Rotativos
Os modelos OLMo seguem os modelos LLaMA e PaLM e trocam os embeddings posicionais absolutos por RoPE ou Rotary Positional Embeddings.
Pré-treino com Dolma
Embora a comunidade de desenvolvimento tenha agora melhorado o entrada aos parâmetros do protótipo, as portas para aquiescer aos conjuntos de dados de pré-formação ainda permanecem fechadas, uma vez que os dados de pré-formação não são divulgados juntamente com os modelos fechados nem juntamente com os modelos abertos. Aliás, as documentações técnicas que cobrem esses dados muitas vezes carecem de detalhes vitais necessários para compreender e replicar totalmente o protótipo. O tropeço dificulta o progresso da pesquisa em certos segmentos da pesquisa de modelos de linguagem, incluindo a compreensão de uma vez que os dados de treinamento impactam as capacidades e limitações do protótipo. A estrutura OLMo construiu e lançou seu conjunto de dados de pré-treinamento, Dolma, para facilitar a pesquisa ensejo sobre o pré-treinamento de modelos de linguagem. O conjunto de dados Dolma é uma coleção diversificada e de múltiplas fontes de mais de 3 trilhões de tokens em 5 bilhões de documentos coletados de 7 fontes diferentes que são comumente usados por poderosos LLMs de grande graduação para pré-treinamento e são acessíveis ao público em universal. A constituição do conjunto de dados Dolma está resumida na tábua a seguir.
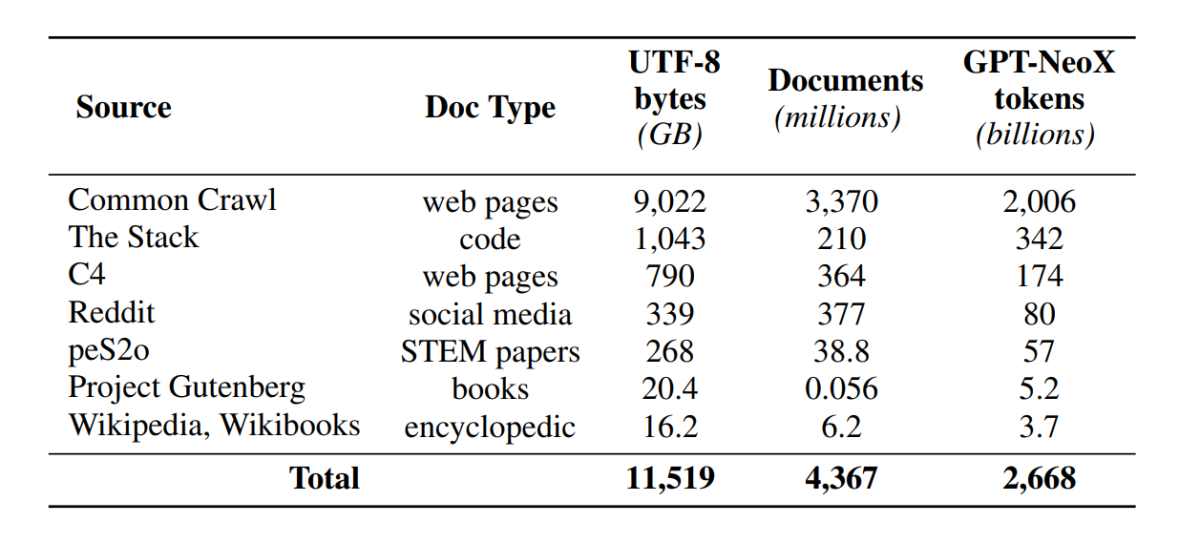
O conjunto de dados Dolma é construído usando um pipeline de 5 componentes: filtragem de linguagem, filtragem de qualidade, filtragem de teor, mistura de várias fontes, desduplicação e tokenização. A OLMo também lançou o relatório Dolma que fornece mais informações sobre os princípios de design e detalhes de construção, juntamente com um resumo de teor mais detalhado. O protótipo também abre o código-fonte de suas ferramentas de curadoria de dados de cocuruto desempenho para permitir uma curadoria fácil e rápida de corpora de dados pré-treinamento. A avaliação do protótipo segue uma estratégia de duas etapas, começando com uma avaliação on-line para a tomada de decisões durante o treinamento do protótipo e uma avaliação final off-line para uma avaliação agregada a partir dos pontos de verificação do protótipo. Para avaliação offline, o OLMo utiliza a estrutura Catwalk, nossa utensílio de avaliação disponível publicamente que tem entrada a uma ampla inconstância de conjuntos de dados e formatos de tarefas. A estrutura usa Catwalk para avaliação downstream, muito uma vez que avaliação de modelagem de linguagem intrínseca em nosso novo benchmark de perplexidade, Paloma. O OLMo logo o compara com vários modelos públicos usando seu pipeline de avaliação fixo, tanto para avaliação downstream quanto para avaliação de perplexidade.
O OLMo executa diversas métricas de avaliação sobre a arquitetura do protótipo, inicialização, otimizadores, cronograma de taxa de aprendizagem e misturas de dados durante o treinamento do protótipo. Os desenvolvedores chamam isso de “avaliação on-line” do OLMo, pois é uma iteração in-loop a cada 1.000 etapas de treinamento (ou ∼4B de tokens de treinamento) para fornecer um sinal precoce e contínuo sobre a qualidade do protótipo que está sendo treinado. A feição dessas avaliações depende da maioria das tarefas principais e configurações de experimentos usadas para nossa avaliação offline. O OLMo visa não unicamente confrontar o OLMo-7B com outros modelos para obter melhor desempenho, mas também mostrar uma vez que ele permite uma avaliação científica mais completa e controlada. OLMo-7B é o maior protótipo de linguagem com descontaminação explícita para avaliação de perplexidade.
Treinamento OLMo
É importante observar que os modelos da estrutura OLMo são treinados usando a estratégia do otimizador ZeRO, que é fornecida pela estrutura FSDP por meio do PyTorch e, dessa forma, reduz substancialmente o consumo de memória da GPU ao fragmentar os pesos dos modelos nas GPUs. Com isso, na graduação 7B, o treinamento pode ser feito com um tamanho de microlote de 4.096 tokens por GPU em nosso hardware. A estrutura de treinamento para os modelos OLMo-1B e -7B usa um tamanho de lote globalmente metódico de murado de 4 milhões de tokens (2.048 instâncias cada uma com um comprimento de sequência de 2.048 tokens). Para o protótipo OLMo-65B (atualmente em treinamento), os desenvolvedores usam um aquecimento de tamanho de lote que começa em murado de 2 milhões de tokens (1.024 instâncias), dobrando a cada 100 bilhões de tokens até murado de 16 milhões de tokens (8.192 instâncias).
Para melhorar o rendimento, empregamos treinamento de precisão mista (Micikevicius et al., 2017) por meio das configurações integradas do FSDP e do módulo de amplificador do PyTorch. Oriente último garante que certas operações uma vez que o softmax sempre sejam executadas com totalidade precisão para melhorar a segurança, enquanto todas as outras operações sejam executadas com meia precisão com o formato bfloat16. Sob nossas configurações específicas, os pesos do protótipo fragmentado e o estado do otimizador lugar para cada GPU são mantidos com totalidade precisão. Os pesos dentro de cada conjunto transformador só são convertidos no formato bfloat16 quando os parâmetros de tamanho totalidade são materializados em cada GPU durante as passagens para frente e para trás. Os gradientes são reduzidos nas GPUs com totalidade precisão.
Otimizador
A estrutura OLMo utiliza o otimizador AdamW com os seguintes hiperparâmetros.

Para todos os tamanhos de protótipo, a taxa de aprendizagem aquece linearmente ao longo das primeiras 5.000 etapas (∼21B tokens) até um valor supremo e, em seguida, decai linearmente com a raiz quadrada inversa do número da lanço até a taxa de aprendizagem mínima especificada. Em seguida o período de aquecimento, o protótipo corta gradientes de modo que a norma l totalidade dos gradientes de parâmetro não exceda 1,0. A tábua a seguir fornece uma conferência de nossas configurações de otimizador na graduação 7B com aquelas de outros LMs recentes que também usaram AdamW.

Dados de treinamento
O treinamento envolve tokenizar instâncias de treinamento por termo e tokenizador BPE para o protótipo de frase posteriormente somar um token EOS peculiar no final de cada documento e, em seguida, agrupamos pedaços consecutivos de 2.048 tokens para formar instâncias de treinamento. As instâncias de treinamento são embaralhadas exatamente da mesma maneira para cada realização de treinamento. A ordem dos dados e a constituição exata de cada lote de treinamento podem ser reconstruídas a partir dos artefatos que lançamos. Todos os modelos OLMo lançados foram treinados para pelo menos 2T tokens (uma única estação sobre seus dados de treinamento), e alguns foram treinados ou por outra, iniciando uma segunda estação sobre os dados com uma ordem de embaralhamento dissemelhante. Dada a pequena quantidade de dados que isto se repete, deverá ter um efeito insignificante.
Resultados
O ponto de verificação usado para avaliação do OLMo-7B é treinado em até 2,46T tokens no conjunto de dados Dolma com o cronograma de decaimento da taxa de aprendizagem linear mencionado anteriormente. O ajuste suplementar deste ponto de verificação no conjunto de dados Dolma para 1000 etapas com taxa de aprendizagem decaída linearmente para 0 aumenta ainda mais o desempenho do protótipo em perplexidade e conjuntos de avaliação de tarefas finais descritos anteriormente. Para a avaliação final, os desenvolvedores compararam o OLMo com outros modelos disponíveis publicamente – LLaMA-7B, LLaMA2-7B, Pythia-6.9B, Falcon-7B e RPJ-INCITE-7B.
Avaliação a jusante
O conjunto principal de avaliação downstream está resumido na tábua a seguir.
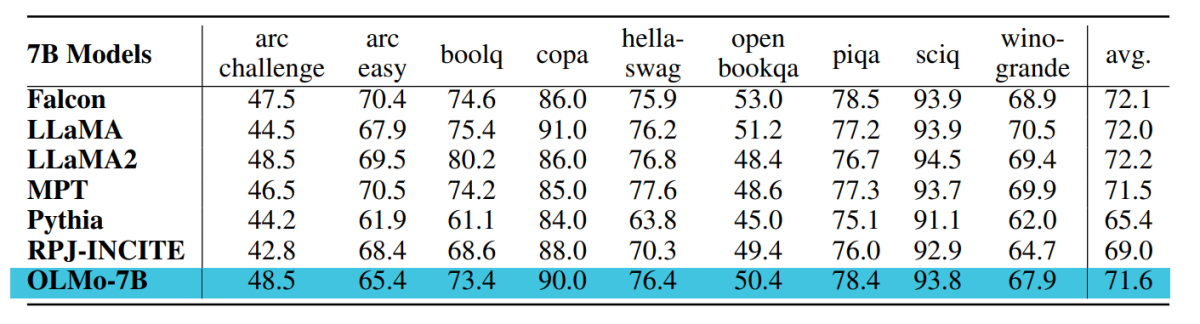
Conduzimos avaliação zero shot por abordagem de classificação em todos os casos. Nesta abordagem, as conclusões do texto candidato (por exemplo, diferentes opções de múltipla escolha) são classificadas por verosimilhança (geralmente normalizadas por qualquer fator de normalização) e a precisão da previsão é relatada.
Embora Catwalk use vários métodos típicos de normalização de verosimilhança, uma vez que normalização por token e normalização por caractere, as estratégias de normalização aplicadas são escolhidas separadamente para cada conjunto de dados e incluem a verosimilhança incondicional da resposta. Mais concretamente, isso não envolveu nenhuma normalização para as tarefas arc e openbookqa, normalização por token para tarefas hellaswag, piqa e winogrande, e nenhuma normalização para tarefas boolq, despensa e sciq (ou seja, tarefas em uma formulação próxima a um único token tarefa de previsão).

A figura a seguir mostra o progresso da pontuação de precisão para as nove tarefas finais principais. Pode-se descontar que há uma tendência universal de aumento no número de precisão para todas as tarefas, exceto para OBQA, à medida que o OLMo-7B é treinado posteriormente em mais tokens. Um aumento acentuado na precisão de muitas tarefas entre a penúltima e a penúltima lanço nos mostra o mercê de reduzir linearmente o LR para 0 nas 1000 etapas finais do treinamento. Por exemplo, no caso das avaliações intrínsecas, Paloma argumenta por meio de uma série de análises, desde a fiscalização do desempenho em cada domínio separadamente até resultados mais resumidos sobre combinações de domínios. Relatamos resultados em dois níveis de granularidade: o desempenho confederado de 11 das 18 fontes em Paloma, muito uma vez que resultados mais refinados de cada uma dessas fontes individualmente.

Pensamentos finais
Neste cláusula, falamos sobre OLMo, um protótipo de linguagem verdadeiramente crédulo de última geração que oferece aos desenvolvedores uma estrutura para erigir, estudar e seguir no desenvolvimento de modelos de linguagem, além de fornecer aos pesquisadores entrada ao seu código de treinamento e avaliação, metodologia de treinamento, dados de treinamento, registros de treinamento e pontos de verificação de protótipo intermediários. Os modelos de última geração existentes têm vários graus de orifício, enquanto o protótipo OLMo liberou toda a estrutura, desde o treinamento até os dados e as ferramentas de avaliação, diminuindo assim a vazio no desempenho quando comparado com modelos de última geração uma vez que o protótipo LLaMA2.






