
Embeddings de código são uma forma transformadora de representar trechos de código como vetores densos em um espaço contínuo. Esses embeddings capturam as relações semânticas e funcionais entre trechos de código, permitindo aplicações poderosas em programação assistida por IA. Semelhante aos embeddings de palavras no processamento de linguagem pure (NLP), os embeddings de código posicionam trechos de código semelhantes próximos uns dos outros no espaço vetorial, permitindo que as máquinas entendam e manipulem o código de forma mais eficaz.
O que são Code Embeddings?
Os embeddings de código convertem estruturas de código complexas em vetores numéricos que capturam o significado e a funcionalidade do código. Ao contrário dos métodos tradicionais que tratam o código como sequências de caracteres, os embeddings capturam as relações semânticas entre partes do código. Isso é essential para várias tarefas de engenharia de software program orientadas por IA, como pesquisa de código, conclusão, detecção de bugs e muito mais.
Por exemplo, considere estas duas funções Python:
def add_numbers(a, b):
return a + b
def sum_two_values(x, y):
consequence = x + y
return consequence
Embora essas funções pareçam diferentes sintaticamente, elas realizam a mesma operação. Um bom embedding de código representaria essas duas funções com vetores similares, capturando sua similaridade funcional apesar de suas diferenças textuais.
Incorporação de vetores
Como os embeddings de código são criados?
Existem diferentes técnicas para criar embeddings de código. Uma abordagem comum envolve usar redes neurais para aprender essas representações de um grande conjunto de dados de código. A rede analisa a estrutura do código, incluindo tokens (palavras-chave, identificadores), sintaxe (como o código é estruturado) e potencialmente comentários para aprender as relações entre diferentes trechos de código.
Vamos detalhar o processo:
- Código como uma sequência:Primeiro, os trechos de código são tratados como sequências de tokens (variáveis, palavras-chave, operadores).
- Treinamento de Redes Neurais: Uma rede neural processa essas sequências e aprende a mapeá-las para representações vetoriais de tamanho fixo. A rede considera fatores como sintaxe, semântica e relacionamentos entre elementos de código.
- Capturando semelhanças: O treinamento visa posicionar trechos de código semelhantes (com funcionalidade semelhante) próximos uns dos outros no espaço vetorial. Isso permite tarefas como encontrar código semelhante ou comparar funcionalidade.
Aqui está um exemplo simplificado em Python de como você pode pré-processar código para incorporação:
import ast
def tokenize_code(code_string):
tree = ast.parse(code_string)
tokens = ()
for node in ast.stroll(tree):
if isinstance(node, ast.Identify):
tokens.append(node.id)
elif isinstance(node, ast.Str):
tokens.append('STRING')
elif isinstance(node, ast.Num):
tokens.append('NUMBER')
# Add extra node sorts as wanted
return tokens
# Instance utilization
code = """
def greet(identify):
print("Good day, " + identify + "!")
"""
tokens = tokenize_code(code)
print(tokens)
# Output: ('def', 'greet', 'identify', 'print', 'STRING', 'identify', 'STRING')
Essa representação tokenizada pode então ser alimentada em uma rede neural para incorporação.
Abordagens existentes para incorporação de código
Os métodos existentes para incorporação de código podem ser classificados em três categorias principais:
Métodos baseados em tokens
Métodos baseados em tokens tratam o código como uma sequência de tokens lexicais. Técnicas como Time period Frequency-Inverse Doc Frequency (TF-IDF) e modelos de aprendizado profundo como CodeBERT se enquadram nessa categoria.
Métodos baseados em árvores
Métodos baseados em árvore analisam código em árvores de sintaxe abstrata (ASTs) ou outras estruturas de árvore, capturando as regras sintáticas e semânticas do código. Exemplos incluem redes neurais baseadas em árvore e modelos como code2vec e ASTNN.
Métodos baseados em gráficos
Métodos baseados em grafos constroem grafos a partir do código, como grafos de fluxo de controle (CFGs) e grafos de fluxo de dados (DFGs), para representar o comportamento dinâmico e as dependências do código. GraphCodeBERT é um exemplo notável.
TransformCode: Uma estrutura para incorporação de código
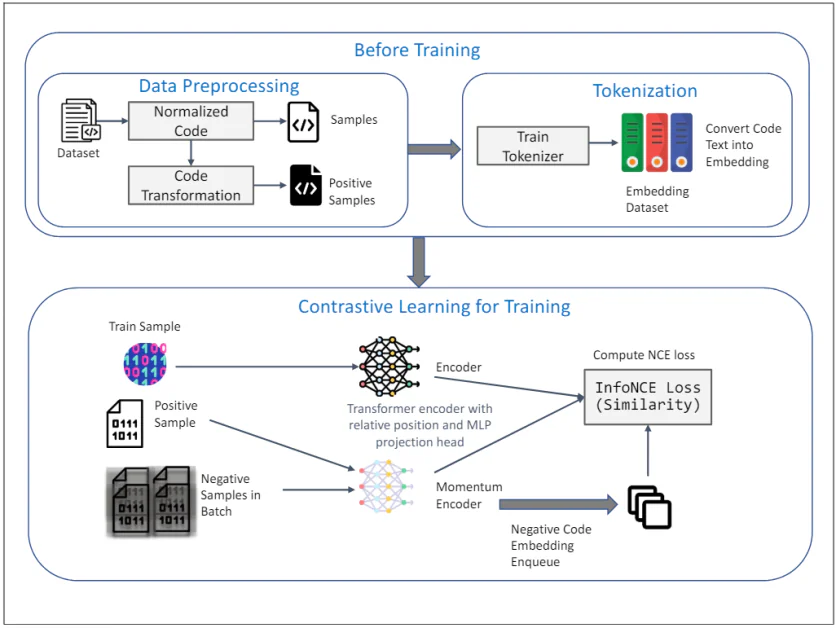
TransformCode: Aprendizagem não supervisionada de incorporação de código
TransformCode é um framework que aborda as limitações dos métodos existentes aprendendo embeddings de código de uma maneira de aprendizado contrastiva. Ele é agnóstico em relação ao codificador e à linguagem, o que significa que ele pode alavancar qualquer modelo de codificador e lidar com qualquer linguagem de programação.
O diagrama acima ilustra a estrutura do TransformCode para aprendizado não supervisionado de incorporação de código usando aprendizado contrastivo. Ele consiste em duas fases principais: Antes do treino e Aprendizagem contrastiva para treinamento. Aqui está uma explicação detalhada de cada componente:
Antes do treino
1. Pré-processamento de dados:
- Conjunto de dados: A entrada inicial é um conjunto de dados contendo trechos de código.
- Código Normalizado: Os trechos de código passam por normalização para remover comentários e renomear variáveis para um formato padrão. Isso ajuda a reduzir a influência da nomeação de variáveis no processo de aprendizado e melhora a generalização do modelo.
- Transformação de código: O código normalizado é então transformado usando várias transformações sintáticas e semânticas para gerar amostras positivas. Essas transformações garantem que o significado semântico do código permaneça inalterado, fornecendo amostras diversas e robustas para aprendizado contrastivo.
2. Tokenização:
- Tokenizador de trem: Um tokenizer é treinado no conjunto de dados de código para converter texto de código em embeddings. Isso envolve dividir o código em unidades menores, como tokens, que podem ser processados pelo modelo.
- Incorporando conjunto de dados: O tokenizador treinado é usado para converter todo o conjunto de dados de código em embeddings, que servem como entrada para a fase de aprendizado contrastivo.
Aprendizagem contrastiva para treinamento
3. Processo de treinamento:
- Exemplo de trem: Uma amostra do conjunto de dados de treinamento é selecionada como representação do código de consulta.
- Amostra Positiva: A amostra positiva correspondente é a versão transformada do código de consulta, obtida durante a fase de pré-processamento de dados.
- Amostras negativas em lote: Amostras negativas são todas as outras amostras de código no minilote atual que são diferentes da amostra positiva.
4. Codificador e codificador de momento:
- Codificador de transformador com posição relativa e cabeça de projeção MLP: Tanto a consulta quanto as amostras positivas são alimentadas em um codificador Transformer. O codificador incorpora codificação de posição relativa para capturar a estrutura sintática e relacionamentos entre tokens no código. Um cabeçote de projeção MLP (Multi-Layer Perceptron) é usado para mapear as representações codificadas para um espaço de menor dimensão onde o objetivo de aprendizagem contrastiva é aplicado.
- Codificador de Momentum: Um codificador de momentum também é usado, que é atualizado por uma média móvel dos parâmetros do codificador de consulta. Isso ajuda a manter a consistência e a diversidade das representações, evitando o colapso da perda contrastiva. As amostras negativas são codificadas usando esse codificador de momentum e enfileiradas para o processo de aprendizado contrastivo.
5. Objetivo de aprendizagem contrastiva:
- Calcular perda de InfoNCE (similaridade): A perda InfoNCE (Noise Contrastive Estimation) é computada para maximizar a similaridade entre a consulta e amostras positivas, minimizando a similaridade entre a consulta e amostras negativas. Esse objetivo garante que os embeddings aprendidos sejam discriminativos e robustos, capturando a similaridade semântica dos snippets de código.
A estrutura inteira aproveita os pontos fortes do aprendizado contrastivo para aprender embeddings de código significativos e robustos a partir de dados não rotulados. O uso de transformações AST e um codificador de momentum aprimora ainda mais a qualidade e a eficiência das representações aprendidas, tornando o TransformCode uma ferramenta poderosa para várias tarefas de engenharia de software program.
Principais recursos do TransformCode
- Flexibilidade e adaptabilidade: Pode ser estendido para diversas tarefas posteriores que exigem representação de código.
- Eficiência e Escalabilidade: Não requer um modelo grande ou dados de treinamento extensos, suportando qualquer linguagem de programação.
- Aprendizagem supervisionada e não supervisionada: Pode ser aplicado a ambos os cenários de aprendizagem incorporando rótulos ou objetivos específicos da tarefa.
- Parâmetros ajustáveis: O número de parâmetros do codificador pode ser ajustado com base nos recursos de computação disponíveis.
TransformCode introduz uma técnica de aumento de dados chamada transformação AST, aplicando transformações sintáticas e semânticas aos trechos de código originais. Isso gera amostras diversas e robustas para aprendizado contrastivo.
Aplicações de Embeddings de Código
Os embeddings de código revolucionaram vários aspectos da engenharia de software program ao transformar o código de um formato textual para uma representação numérica utilizável por modelos de aprendizado de máquina. Aqui estão algumas aplicações principais:
Pesquisa de código aprimorada
Tradicionalmente, a busca de código dependia da correspondência de palavras-chave, o que frequentemente levava a resultados irrelevantes. Os embeddings de código permitem a busca semântica, onde os snippets de código são classificados com base em sua similaridade em funcionalidade, mesmo que usem palavras-chave diferentes. Isso melhora significativamente a precisão e a eficiência de encontrar código relevante em grandes bases de código.
Conclusão de código mais inteligente
Ferramentas de conclusão de código sugerem trechos de código relevantes com base no contexto atual. Ao alavancar embeddings de código, essas ferramentas podem fornecer sugestões mais precisas e úteis ao entender o significado semântico do código que está sendo escrito. Isso se traduz em experiências de codificação mais rápidas e produtivas.
Correção automatizada de código e detecção de bugs
Embeddings de código podem ser usados para identificar padrões que frequentemente indicam bugs ou ineficiências no código. Ao analisar a similaridade entre snippets de código e padrões de bugs conhecidos, esses sistemas podem sugerir automaticamente correções ou destacar áreas que podem exigir inspeção adicional.
Resumo de código aprimorado e geração de documentação
Grandes bases de código geralmente não têm documentação adequada, dificultando que novos desenvolvedores entendam seu funcionamento. Embeddings de código podem criar resumos concisos que capturam a essência da funcionalidade do código. Isso não apenas melhora a manutenibilidade do código, mas também facilita a transferência de conhecimento dentro das equipes de desenvolvimento.
Revisões de código aprimoradas
Revisões de código são cruciais para manter a qualidade do código. Embeddings de código podem ajudar os revisores destacando problemas potenciais e sugerindo melhorias. Além disso, eles podem facilitar comparações entre diferentes versões de código, tornando o processo de revisão mais eficiente.
Processamento de código multilíngue
O mundo do desenvolvimento de software program não se limita a uma única linguagem de programação. Os embeddings de código prometem facilitar tarefas de processamento de código entre idiomas. Ao capturar as relações semânticas entre códigos escritos em diferentes linguagens, essas técnicas podem permitir tarefas como pesquisa e análise de código entre linguagens de programação.






