

O Gemma 2 se baseia em seu antecessor, oferecendo desempenho e eficiência aprimorados, juntamente com um conjunto de recursos inovadores que o tornam particularmente atraente para aplicações práticas e de pesquisa. O que diferencia o Gemma 2 é sua capacidade de fornecer desempenho comparável a modelos proprietários muito maiores, mas em um pacote projetado para acessibilidade e uso mais amplos em configurações de {hardware} mais modestas.
Conforme me aprofundava nas especificações técnicas e na arquitetura do Gemma 2, fiquei cada vez mais impressionado com a engenhosidade de seu design. O modelo incorpora várias técnicas avançadas, incluindo novos mecanismos de atenção e abordagens inovadoras para treinar estabilidade, que contribuem para suas capacidades notáveis.
Google Open Supply LLM Gemma
Neste guia abrangente, exploraremos o Gemma 2 em profundidade, examinando sua arquitetura, principais recursos e aplicações práticas. Seja você um praticante experiente de IA ou um novato entusiasmado no campo, este artigo tem como objetivo fornecer insights valiosos sobre como o Gemma 2 funciona e como você pode alavancar seu poder em seus próprios projetos.
O que é Gemma 2?
Gemma 2 é o mais novo modelo de linguagem grande de código aberto do Google, projetado para ser leve, mas poderoso. Ele é construído na mesma pesquisa e tecnologia usadas para criar os modelos Gemini do Google, oferecendo desempenho de ponta em um pacote mais acessível. O Gemma 2 vem em dois tamanhos:
Gema 2 9B: Um modelo de 9 bilhões de parâmetros
Gema 2 27B: Um modelo maior de 27 bilhões de parâmetros
Cada tamanho está disponível em duas variantes:
Modelos base: Pré-treinado em um vasto corpus de dados de texto
Modelos ajustados por instrução (TI):Ajustado para melhor desempenho em tarefas específicas
Acesse os modelos no Google AI Studio: Google AI Studio – Gemma 2
Leia o artigo aqui: Relatório técnico Gemma 2
Principais recursos e melhorias
Gemma 2 apresenta vários avanços significativos em relação ao seu antecessor:
1. Aumento de dados de treinamento
Os modelos foram treinados com muito mais dados:
Gema 2 27B: Treinado em 13 trilhões de tokens
Gema 2 9B: Treinado em 8 trilhões de tokens
Esse conjunto de dados expandido, composto principalmente de dados da net (principalmente em inglês), código e matemática, contribui para o melhor desempenho e versatilidade dos modelos.
2. Atenção para janela deslizante
Gemma 2 implementa uma nova abordagem aos mecanismos de atenção:
Cada outra camada usa uma janela deslizante de atenção com um contexto native de 4096 tokens
Camadas alternadas empregam atenção world quadrática completa em todo o contexto de token 8192
Essa abordagem híbrida visa equilibrar a eficiência com a capacidade de capturar dependências de longo alcance na entrada.
3. Cobertura suave
Para melhorar a estabilidade e o desempenho do treinamento, o Gemma 2 introduz um mecanismo de soft-capping:
def soft_cap(x, cap):
return cap * torch.tanh(x / cap)
# Utilized to consideration logits
attention_logits = soft_cap(attention_logits, cap=50.0)
# Utilized to last layer logits
final_logits = soft_cap(final_logits, cap=30.0)
Essa técnica evita que os logits cresçam excessivamente sem truncamento rígido, mantendo mais informações e estabilizando o processo de treinamento.
- Gema 2 9B: Um modelo de 9 bilhões de parâmetros
- Gema 2 27B: Um modelo maior de 27 bilhões de parâmetros
Cada tamanho está disponível em duas variantes:
- Modelos básicos: pré-treinados em um vasto corpus de dados de texto
- Modelos ajustados por instrução (TI): ajustados para melhor desempenho em tarefas específicas
4. Destilação do conhecimento
Para o modelo 9B, Gemma 2 emprega técnicas de destilação de conhecimento:
- Pré-treinamento: O modelo 9B aprende com um modelo de professor maior durante o treinamento inicial
- Pós-treinamento: Os modelos 9B e 27B usam destilação de acordo com a política para refinar seu desempenho
Esse processo ajuda o modelo menor a capturar as capacidades dos modelos maiores de forma mais eficaz.
5. Mesclagem de modelos
Gemma 2 utiliza uma nova técnica de fusão de modelos chamada Warp, que combina múltiplos modelos em três estágios:
- Média Móvel Exponencial (EMA) durante o ajuste fino do aprendizado por reforço
- IntERPolation linear esférica (SLERP) após ajuste fino de várias políticas
- Interpolação Linear para Inicialização (LITI) como etapa last
Essa abordagem visa criar um modelo last mais robusto e capaz.
Benchmarks de desempenho
Gemma 2 demonstra desempenho impressionante em vários benchmarks:

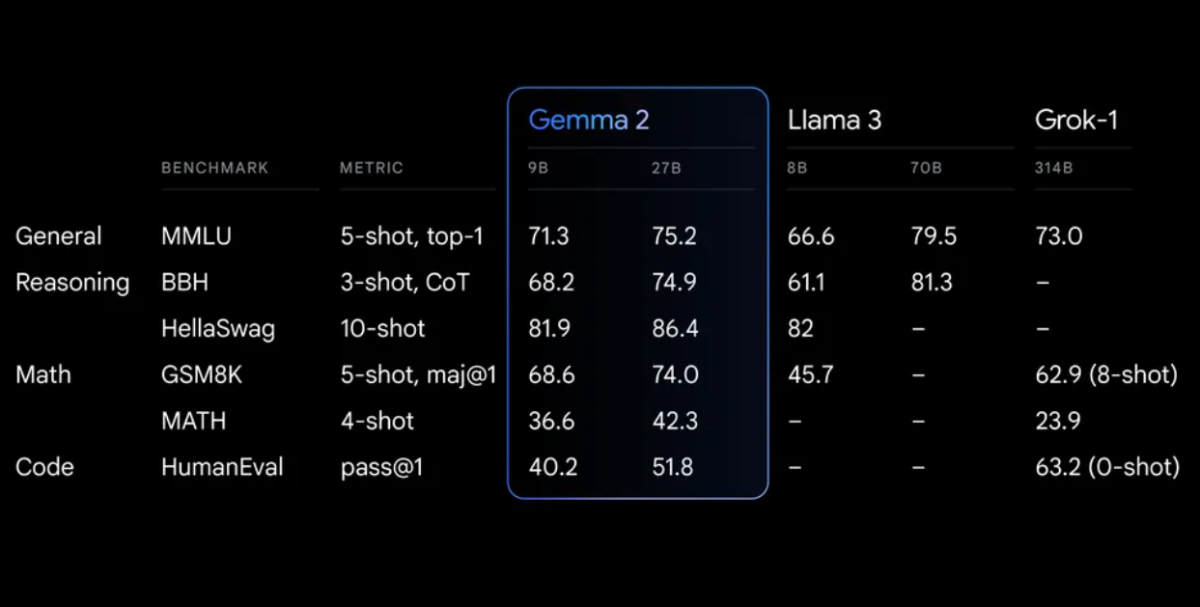
Gemma 2 em uma arquitetura redesenhada, projetada para desempenho excepcional e eficiência de inferência
Introdução ao Gemma 2
Para começar a usar o Gemma 2 em seus projetos, você tem várias opções:
1. Estúdio de IA do Google
Para uma experimentação rápida sem requisitos de {hardware}, você pode acessar o Gemma 2 através do Google AI Studio.
2. Transformadores de rosto que abraçam
Gemma 2 é integrado com a well-liked biblioteca Hugging Face Transformers. Veja como você pode usá-lo:
<div class="relative flex flex-col rounded-lg"> <div class="text-text-300 absolute pl-3 pt-2.5 text-xs"> from transformers import AutoTokenizer, AutoModelForCausalLM # Load the mannequin and tokenizer model_name = "google/gemma-2-27b-it" # or "google/gemma-2-9b-it" for the smaller model tokenizer = AutoTokenizer.from_pretrained(model_name) mannequin = AutoModelForCausalLM.from_pretrained(model_name) # Put together enter immediate = "Clarify the idea of quantum entanglement in easy phrases." inputs = tokenizer(immediate, return_tensors="pt") # Generate textual content outputs = mannequin.generate(**inputs, max_length=200) response = tokenizer.decode(outputs(0), skip_special_tokens=True) print(response)
3. TensorFlow/Onerous
Para usuários do TensorFlow, o Gemma 2 está disponível através do Keras:
import tensorflow as tf
from keras_nlp.fashions import GemmaCausalLM
# Load the mannequin
mannequin = GemmaCausalLM.from_preset("gemma_2b_en")
# Generate textual content
immediate = "Clarify the idea of quantum entanglement in easy phrases."
output = mannequin.generate(immediate, max_length=200)
print(output)
Uso avançado: Construindo um sistema RAG native com Gemma 2
Uma aplicação poderosa do Gemma 2 é na construção de um sistema Retrieval Augmented Technology (RAG). Vamos criar um sistema RAG simples e totalmente native usando o Gemma 2 e os embeddings Nomic.
Etapa 1: Configurando o ambiente
Primeiro, certifique-se de ter as bibliotecas necessárias instaladas:
pip set up langchain ollama nomic chromadb
Etapa 2: Indexação de documentos
Crie um indexador para processar seus documentos:
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import DirectoryLoader
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
class Indexer:
def __init__(self, directory_path):
self.directory_path = directory_path
self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
self.embeddings = HuggingFaceEmbeddings(model_name="nomic-ai/nomic-embed-text-v1")
def load_and_split_documents(self):
loader = DirectoryLoader(self.directory_path, glob="**/*.txt")
paperwork = loader.load()
return self.text_splitter.split_documents(paperwork)
def create_vector_store(self, paperwork):
return Chroma.from_documents(paperwork, self.embeddings, persist_directory="./chroma_db")
def index(self):
paperwork = self.load_and_split_documents()
vector_store = self.create_vector_store(paperwork)
vector_store.persist()
return vector_store
# Utilization
indexer = Indexer("path/to/your/paperwork")
vector_store = indexer.index()
Etapa 3: Configurando o sistema RAG
Agora, vamos criar o sistema RAG usando Gemma 2:
from langchain.llms import Ollama
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
class RAGSystem:
def __init__(self, vector_store):
self.vector_store = vector_store
self.llm = Ollama(mannequin="gemma2:9b")
self.retriever = self.vector_store.as_retriever(search_kwargs={"okay": 3})
self.template = """Use the next items of context to reply the query on the finish.
If you do not know the reply, simply say that you do not know, do not attempt to make up a solution.
{context}
Query: {query}
Reply: """
self.qa_prompt = PromptTemplate(
template=self.template, input_variables=("context", "query")
)
self.qa_chain = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff",
retriever=self.retriever,
return_source_documents=True,
chain_type_kwargs={"immediate": self.qa_prompt}
)
def question(self, query):
return self.qa_chain({"question": query})
# Utilization
rag_system = RAGSystem(vector_store)
response = rag_system.question("What's the capital of France?")
print(response("end result"))
Este sistema RAG usa Gemma 2 até Ollama para o modelo de linguagem e embeddings Nomic para recuperação de documentos. Ele permite que você faça perguntas com base nos documentos indexados, fornecendo respostas com contexto das fontes relevantes.
Ajuste fino da Gemma 2
Para tarefas ou domínios específicos, talvez você queira ajustar o Gemma 2. Aqui está um exemplo básico usando a biblioteca Hugging Face Transformers:
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Coach
from datasets import load_dataset
# Load mannequin and tokenizer
model_name = "google/gemma-2-9b-it"
tokenizer = AutoTokenizer.from_pretrained(model_name)
mannequin = AutoModelForCausalLM.from_pretrained(model_name)
# Put together dataset
dataset = load_dataset("your_dataset")
def tokenize_function(examples):
return tokenizer(examples("textual content"), padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# Arrange coaching arguments
training_args = TrainingArguments(
output_dir="./outcomes",
num_train_epochs=3,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
warmup_steps=500,
weight_decay=0.01,
logging_dir="./logs",
)
# Initialize Coach
coach = Coach(
mannequin=mannequin,
args=training_args,
train_dataset=tokenized_datasets("practice"),
eval_dataset=tokenized_datasets("take a look at"),
)
# Begin fine-tuning
coach.practice()
# Save the fine-tuned mannequin
mannequin.save_pretrained("./fine_tuned_gemma2")
tokenizer.save_pretrained("./fine_tuned_gemma2")
Lembre-se de ajustar os parâmetros de treinamento com base em seus requisitos específicos e recursos computacionais.
Considerações e limitações éticas
Embora o Gemma 2 ofereça recursos impressionantes, é essential estar ciente de suas limitações e considerações éticas:
- Viés: Como todos os modelos de linguagem, Gemma 2 pode refletir vieses presentes em seus dados de treinamento. Sempre avalie criticamente suas saídas.
- Precisão dos fatos: Embora altamente capaz, Gemma 2 pode, às vezes, gerar informações incorretas ou inconsistentes. Verifique fatos importantes de fontes confiáveis.
- Comprimento do contexto: Gemma 2 tem um comprimento de contexto de 8192 tokens. Para documentos ou conversas mais longos, você pode precisar implementar estratégias para gerenciar o contexto de forma eficaz.
- Recursos Computacionais:Especialmente para o modelo 27B, recursos computacionais significativos podem ser necessários para inferência e ajuste fino eficientes.
- Uso Responsável: Siga as práticas de IA responsável do Google e garanta que seu uso do Gemma 2 esteja alinhado aos princípios éticos de IA.
Conclusão
Os recursos avançados do Gemma 2, como atenção de janela deslizante, soft-capping e novas técnicas de fusão de modelos, o tornam uma ferramenta poderosa para uma ampla gama de tarefas de processamento de linguagem pure.
Ao aproveitar o Gemma 2 em seus projetos, seja por meio de inferência simples, sistemas RAG complexos ou modelos ajustados para domínios específicos, você pode aproveitar o poder da IA SOTA enquanto mantém o controle sobre seus dados e processos.






